




AudioWorker’s Basics
Schall, Welle, Frequenz - ein wenig Akustik
Was passiert, wenn wir ein akustisches Ereignis wahrnehmen? Dieses Ereignis stellt sich zunächst einmal dar als Schwingungen des Mediums bzw der Medien, die zwischen uns und dem Auslöser des akustischen Ereignis existieren, also: Luft, Wasser etc.
 Wenn etwa Prof. Redeviel einen Vortrag über digitale Audio-Bearbeitung
im Hörfunk hält, setzt die Bewegung seiner Stimmritze, seines Mundes
und seiner Zunge die Luft, die hier das Medium (der Schallträger) ist, in Schwingung:
Es entstehen Schallwellen.
Wenn etwa Prof. Redeviel einen Vortrag über digitale Audio-Bearbeitung
im Hörfunk hält, setzt die Bewegung seiner Stimmritze, seines Mundes
und seiner Zunge die Luft, die hier das Medium (der Schallträger) ist, in Schwingung:
Es entstehen Schallwellen.
Diese Schallwellen treffen auf das Trommelfell in den Ohren der Zuhörer, auf das die Schwingungen übertragen werden, um dann (wir erinnern uns an unseren Biologielehrer, dessen Monologe Ähnliches bewirkten) im Ohr via Hammer, Amboss, Steigbügel und Gehörschneckenflüssigkeit in Impulse des Gehörnervs übertragen zu werden. Als solche kommen sie schließlich im Gehirn an, wo sie als Sinneseindruck (Schall) wahrgenommen werden. Und solange Prof. Redeviel (nomen est omen) des Redens nicht müde wird, werden unentwegt neue Luftschwingungen entstehen, die diesen Weg gehen.
Messen lassen sich diese Schwingungen entweder am Ort ihrer Entstehung (Prof. Redeviel wird das wahrscheinlich nicht zulassen, aber an einer Guitarrensaite z.B. könnte eine Messung vor Ort stattfinden) oder irgendwo im beschallten Raum mit einem durch die Luftschwingung selbst in Schwingung versetztes Messinstrument (etwa der Membran eines Mikrophons). Die Messung kann dabei in zweierlei Hinsicht erfolgen:
-
Schall- und Lautstärke:
Es lässt sich die Höhe, also die Amplitude der Schwingungen messen, die Aufschluss gibt über den Schalldruck und damit auch über die Lautstärke des akustischen Signals. Allerdings ist hier nur die Schallstärke eine absolute Größe, während sich die Lautstärke auf das menschliche Schallempfinden bezieht. Letztere hängt zwar von der Stärke des äußeren Reizes, des Schalldrucks ab, sie wächst aber viel langsamer als dieser Reiz: Ertönen z.B. erst eine dann zwei Hupen, hat sich die Schallstärke natürlich verdoppelt. Ihre Lautstärke jedoch nicht, da wir die zwei Hupen nicht als doppelt so laut wahrnehmen.Die Maßeinheit für die Lautstärke ist phon, wobei 0 phon die menschliche Hörschwelle beschreibt und 130 phon die Schmerzschwelle. Eine Verdoppelung der Schallstärke erhöht die Lautstärke um etwa 3 phon, eine Verzehnfachung um 10 phon, eine Verhundertfachung um 20 phon. Daneben lässt sich die Lautstärke auch in den, in der Welt der Tontechnik so beliebten Dezibel angeben, als dB(A).
Dezibel geben immer ein Verhältnis zweier Werte an einer logarithmischen Skala an! Wird Lautstärke in Dezibel gemessen, ist der Bezugswert das leiseste Schallereignis, das von einem durchschnittlichen Menschen gerade noch gehört werden kann, modifiziert durch die sog. Bewertungskurve A, die die Eigenschaft des Gehörs berücksichtigt, verschiedene Frequenzen unterschiedlich laut wahrzunehmen.
Dieser dB-Wert hat mithin wenig bis gar nichts mit den db-Angaben auf einem Austeuerungsmesser zu tun, der sich (wie wir noch sehen werden) auf elektrische Spannung(en) bezieht! -
Frequenz:
Neben der Höhe kann auch die Länge einer Schwingung gemessen werden bzw. die Anzahl periodischer Schwingungen pro Zeiteinheit - die Frequenz*.Genaugenommen sind Schwingungslänge und Frequenz natürlich verschiedene Größen, deren Zusammenhang abhängig ist von der Schallgeschwindigkeit, die ihrerseits in verschiedenen Medien (Luft, Wasser) und bei verschiedenen Temperaturen variiert. Bei gegebenem Medium und gegebener Temperatur entspricht jede Schwingungslänge jedoch einer Frequenz.Die Frequenz der Schwingung bestimmt die wahrgenommene Tonhöhe und wird im Angedenken an den Physiker Heinrich Hertz (1857-1894) in Hertz (Hz) gemessen:
1 Hz = 1 Schwingungsperiode/Sekunde, 1 Kilohertz (kHz) = 1000 Hz.Das menschliche Ohr kann Schall nur in einem Frequenzbereich zwischen 16 Hz bis 20.000 Hz wahrnehmen, wobei die obere Hörgrenze zum Schrecken aller Toningenieure und anderer lärmender Berufsgruppen mit zunehmendem Alter deutlich sinkt. Der Bereich unter 16 Hz wird Infraschall genannt und spielt in der Tierkommunikation (Wale, Elefanten) eine Rolle; der Bereich oberhalb von 20.000 Hz Ultraschall.
In der Natur lassen sich periodische und nicht-periodische Schwingungen feststellen: Während Geräusche sich in der Regel aus nicht-periodischen Schwingungen zusammensetzen, bestehen Töne und musikalische Klänge aus periodischen Schwingungen. Der Kurvenverlauf periodischer Schwingungen lässt sich dabei oft durch sog. Sinusschwingungen beschreiben: Selten als einfache, reine Sinusschwingung (z.B. bei Pendel, Stimmgabel o.ä.), zumeist als komplexe, aus sich überlagernden Sinusschwingen zusammengesetzte (addierte) Schwingung (s. Abb.1).
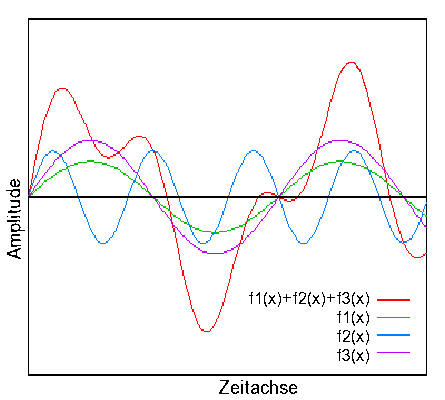
Schon Musikinstrumente z.B. geben durch materialbedingt beim Spielen entstehende Obertöne keine reinen Sinusschwingungen ab und klingen daher beim Spielen eines Tons mit derselben Frequenz, etwa des Kammertons a (440 Hz) durchaus unterschiedlich.
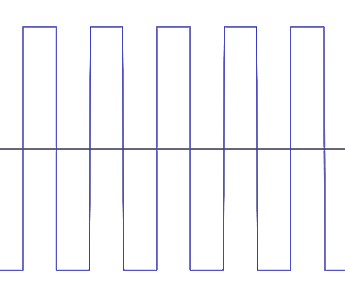
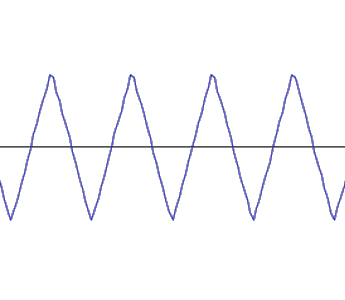
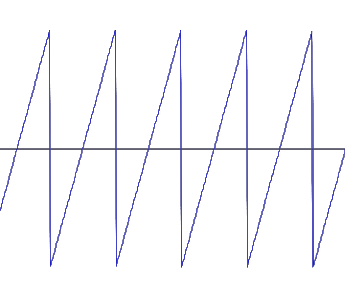
Neben diesen einfachen oder addierten Sinusschwingungen gibt es auch andere periodische Schwingungen wie die Rechteck-, die Dreieck- oder die Sägezahnschwingung. Auch diese lassen sich zwar letztlich auf reine Sinusschwingungen zurückführen; in der Audiotechnik spiel(t)en sie jedoch eine besondere Rolle, da sie sich technisch leichter herstellen lassen, als reine Sinusschwingungen. Man sollte sie daher mal gesehen (und gehört) haben:
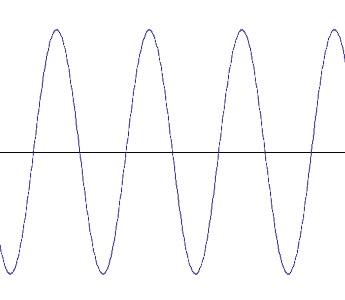
|
Sinus 440 Hz:
|
|
Rechteckschwingung 440 Hz:
|
|
Dreieckschwingung 440 Hz:
|
|
Sägezahnschwingung 440 Hz:
|
Ton als Pegelabfolge - ein wenig Mathematik
Eine akustische Schwingung ist also, wie wir gesehen haben, durch zwei Charaktermerkmale bestimmt: Ihre Länge bzw. Frequenz und ihre Stärke, also Amplitude.
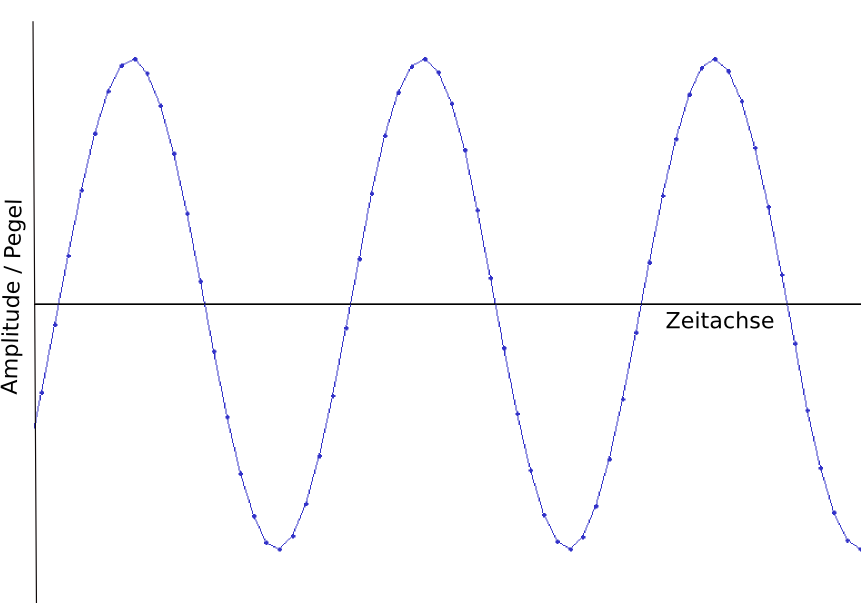
Für das Verständnis all dessen, was bei elektrischer und vor allem bei digitaler Übertragung und Aufzeichnung dieser Schwingungen passiert, ist es wichtig, sich klar zu machen, dass die Gestalt einer Schwingung mathematisch auch durch regelmäßige Abtastung ihrer Auslenkung (also der “Höhe” der Kurve) bestimmt, genauer: aus den bei dieser Abtastung gewonnenen Werten interpoliert werden kann. Statt durch Frequenz und Amplitude kann die Schwingung also auch als eine Folge von Pegelabtastungen in definierten regelmäßigen Zeitabständen beschrieben werden.
Der im obigen Bild gezeigte Sinuston kann also auch dargestellt werden als eine Reihe von z.B. 22.500 Abtastungen pro Sekunde; aus
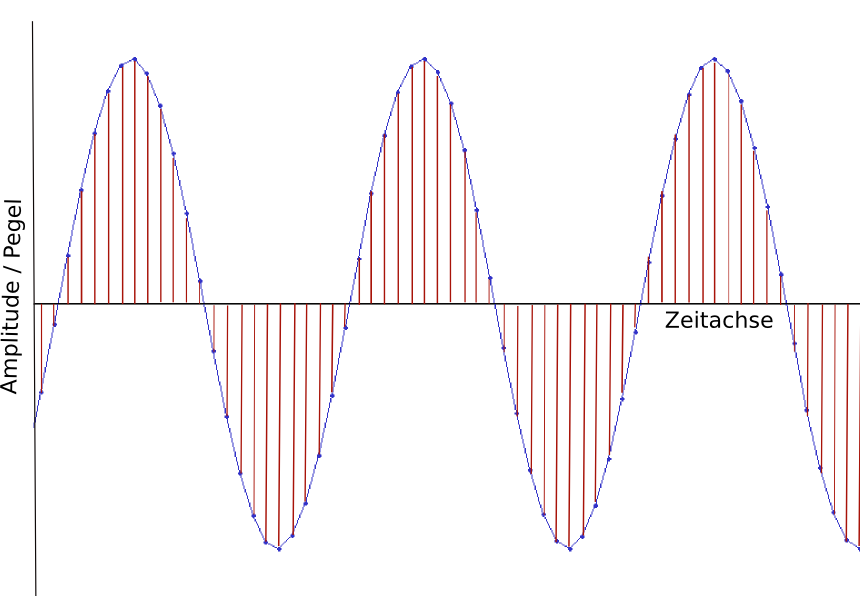
wird so:
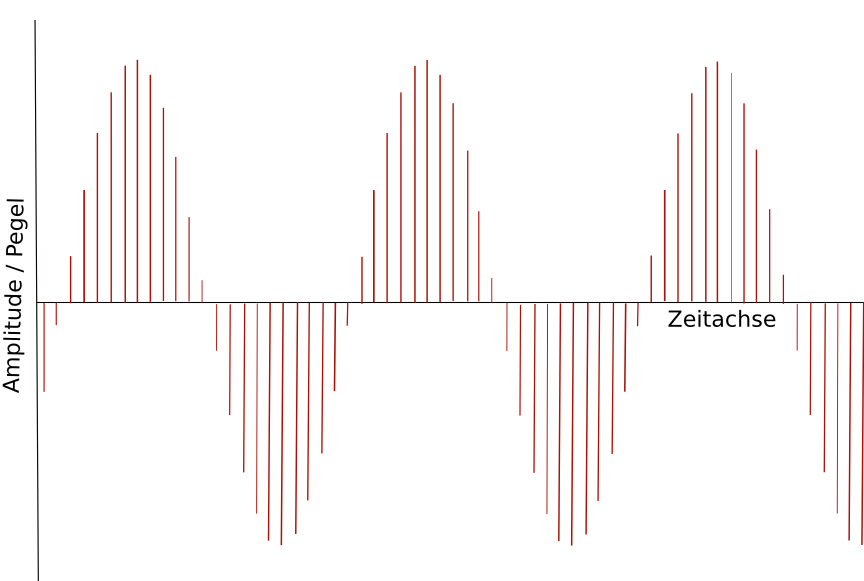
Bei einer solchen Beschreibung der Schwingung als Folge von Pegelabtastungen ist allerdings dreierlei festzustellen:
-
Die Häufigkeit der Abtastung des Pegels (der Schwingungsauslenkung) pro Zeiteinheit, die sog. Abtastrate, muss bei Aufnahme, Übertragung und Wiedergabe gleich bleiben, da die dargestellten Schwingungen ansonsten gestreckt oder gestaucht werden. Wie sich das anhört, weiß jeder, der schon einmal ein Tonband oder eine Schallplatte mit der falschen Geschwindigkeit abgespielt hat: Die Frequenzen der Aufnahme werden falsch wiedergegeben (Stimmen etwa verwandeln sich in schnelle, hochfrequente Mickey-Mouse- oder langsame, tieffrequente Bass-Stimmen).
-
Da bei Darstellung der Schwingung als Folge von Pegelabtastungen der wirkliche Verlauf der Schwingung zwischen zwei Abtastungen nur durch Interpolation, und damit nur angenähert ermittelt (approximiert) werden kann, steigt die Genauigkeit der Darstellung des Signals mit steigender Abtastrate.
Ideal wäre eine unendlich große Abtastrate, eine vollständig lückenlose Abtastung des Signals, wie sie im Prinzip bei der analogen Aufnahme, Übertragung und Speicherung erfolgt: Hier findet überhaupt kein Sampling statt*, da die Schwankungen des Signal-Pegels, wie wir noch sehen werden, immer direkt von einem Medium in ein anderes übertragen werden.Auch hier kann es freilich materialbedingte Diskontinuitäten der Pegel-'Abtastung' geben, etwa durch die Trägheit der Mikrophon- oder Lautsprecher-Membran, die Dichte der Eisenoxid-Moleküle auf einem Tonband o.ä., die sich auf den Frequenzgang auswirken und damit zu einer Reduzierung der maximal möglichen Qualität bei Nutzung dieses Materials führen. -
Bei jeder zwar kontinuierlichen, aber lückenhaften (diskreten) Abtastung gibt es je nach Frequenz (bzw. Länge) der Schwingung zudem eine minimale Abtastrate, einen minimal erforderlichen Zeitabstand der Pegelabtastungen voneinander, um diese Schwingung überhaupt noch annähernd richtig darstellen zu können.
Diesen Zusammenhang zwischen Abtastrate und Qualität der Schwingungsdarstellung haben bereits in der ersten Hälfte des 20. Jahrhunderts verschiedene Mathematiker und Elektrotechniker untersucht. Ausgehend von Überlegungen des Mathematikers Harry Nyquist zur Übertragung endlicher Zahlenfolgen mittels trigonometrischer Polynome wurde schließlich das sog. Nyquist-Shannon- oder auch W(hittaker)-K(otelnikow)-S(hannon)-Abtasttheorem entwickelt. Etwas vereinfacht2 besagt es, dass die minimale Abtastrate eines Audiosignals mindestens doppelt so hoch sein muss, wie die maximal darzustellende Frequenz des Signals, um das Ursprungssignal aus diskreten Abtastungen mit unendlichem Aufwand exakt rekonstruieren und mit endlichem Aufwand beliebig genau approximieren (annähern) zu können. Die minimale Abtastrate ist also:
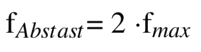
Wird eine zu kleine Abtastrate gewählt, treten sog. Artefakte oder Alias- Effekte auf; im Extremfall unterscheidet sich das rekonstruierte Signal vollständig vom ursprünglichen Signal.
Sehr anschaulich wird dies, wenn wir uns einen 10 Sekunden langen, von 100 Hz bis 16.000 Hz linear ansteigenden Sinuston anhören. (Die Älteren unter uns können hier auch gleich prüfen, ob sie die 16.000 Hz überhaupt noch hören.)
Einmal zeichnen wir diesen Ton mit einer Abtastrate von 32.000 Hz auf, haben also zu jedem Zeitpunkt des Signals eine Abtastrate, die mehr als doppelt so groß ist wie die Frequenz des Tons. Wir hören den Ton (soweit unser Alter dies zulässt) bis zum Ende ansteigen:
Im zweiten Fall zeichnen wir denselben ansteigenden Sinuston mit einer Abtastrate von nur 16.000 Hz auf, haben also nach der Hälfte des Signals eine Abtastrate, die kleiner ist als das Doppelte der Frequenz des wiedergegebenen Tons. Und: Der Ton steigt ab diesem Zeitpunkt nicht mehr an, sondern fällt wieder ab! (*)
Zur Beruhigung der Nerven aller Digital-Audio-Worker muss hier allerdings auch gesagt werden, dass es gar nicht so einfach ist, ein solches Hörbeispiel zu erstellen. Denn jeder Programmierer von Audio-Software ist sich natürlich der Gefahr von Alias-Effekten beim Speichern in zu niedrigen Sampleraten bewußt. Dem Abspeichern wird daher in der Regel ein Low-Pass-Filter vorgeschaltet, der alle Frequenzen oberhalb der halben Abtast-Frequenz des Zielformats aus dem zu speichernden Audio herausfiltert.
Würden wir also unsere mit 32.000 Hz aufgezeichnete Beispiel-Datei im einem Soundbearbeitungsprogramm als Datei mit einer Samplingrate von 16.000 Hz abspeichern, erhielten wir nicht unser zweites Hörbeispiel, da vor dem Speichern alle Frequenzen oberhalb von 8.000 Hz herausgefiltert würden. Ab der Hälfte wäre das so abgespeichert Signal daher Digital-Null. Aus:

würde:

Die zweite Datei unseres Hörbeispiels wurde daher mit SoX erstellt, dem Swiss army knife of sound processing. SoX bietet die Option, jeden zweiten Pegelwerteintrag in einer Audiodatei ungeachtet aller entstehenden Alias-Effekte zu entfernen, was faktisch einer Halbierung der Abtastrate entspricht:
sox Sinus-asc_100-16000Hz_in32kHz.wav Sinus-asc_100-16000Hz_in16kHz.wav downsample 2
Die so entstandene, modifizierte Datei hat im Header allerdings noch die falsche ursprüngliche Abtastrate notiert. Auch dies könnte man mit SoX ändern, die Länge des Audios würde sich dann aber logischerweise verdoppeln. Man kann die entstandene Datei jetzt aber auch in einen Audioeditor seiner Wahl laden und als 16KHz-Datei abspeichern. Da der Audioeditor die Datei als 32KHz-Datei lädt, bleibt die Länge des Audios erhalten, und da keine Frequenzen oberhalb von 8 KHz mehr erkannt werden können, hat auch der Low-Pass-Filter beim Speichern in der niedrigeren Samplerate keine Wirkung mehr.
Ton in Strom - elektrische Schall-Übertragung
Was passiert nun, wenn die akustischen (Schall-)Schwingungen auf elektrischem Wege übertragen werden? Im einfachsten Fall haben wir eine Übertragung von einem Mikrophon über einen Verstärker zum Lautsprecher.

Ein Mikrophon verwandelt die akustischen (Luft-)Schwingungen in elektrische Spannungssignale, indem die Luftschwingungen eine dünne, elastisch gelagerte Membran in Schwingung versetzen, deren Schwingung dann durch einen mechanischen oder elektrischen Wandler (Kohle, Elektromagnet, Kondensator) wiederum in entsprechende Spannungsschwankungen übertragen wird.
Diese Spannungsschwankungen können über einen elektrischen Leiter transportiert und evtl. elektrisch verstärkt werden, um in einem Lautsprecher mittels mechanischen oder elektrischen Wandler wieder eine elastisch gelagerte Membran in Schwingung zu versetzen, die dann ihrerseits die Luft in eben jene Schwingungen versetzt, die am Anfang vom Mikrophon aufgefangen wurden.
Betrachten wir den Ton als Strom, also gewissermaßen das, was sich im Kabel befindet, so sehen wir, daß hier eine Folge von Pegelschwankungen übertragen wird, wobei die Abtastung des Pegels kontinuierlich und lückenlos durch die mechanischen oder elektrischen Wandler erfolgt ist, deren technischen Eigenschaften die Qualität der Abtastung bestimmen. Da hier Pegelschwankungen unmittelbar in Spannungsschwankungen übertragen werden, erfolgt keinerlei Sampling. Die ‘Abtastrate’, wenn man diesen Begriff hier überhaupt verwenden will, ist (abhängig von den physikalischen und technischen Eigenschaften der elektrischen Wandler) nahezu unendlich groß und bleibt, da die Übertragung in Echtzeit erfolgt, auf ’natürliche’ Weise erhalten.
-
Die Frequenz unserer Schwingung stellt sich jetzt dar als zeitliche Abfolge von Spannungswechseln, die die Pegelschwankungen unserer Schwingung repräsentieren.
-
Die Schall- bzw. Lautstärke, also der Pegel stellen sich jetzt dar als eine ständig wechselnde Spannung, die zu jedem beliebigen Zeitpunkt in Volt (V) gemessen werden kann. Genauer: als ein ständig wechselndes Spannungsverhältnis zu einer gegebenen Bezugsspannung des elektrischen Systems (nämlich in der Regel seiner maximal zulässigen Eingangsspannung = Vollaussteuerung)
Das Verhältnis zwischen darzustellender Spannung U und Bezugsspannung U(ref), also zwischen darzustellendem Pegel und Bezugspegel wird dabei zumeist logarithmisch in Dezibel dargestellt*, und zwar als:
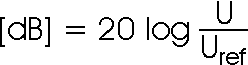
Der Name der Einheit Bel ehrt den Erfinder des Telefons, den Briten und späteren Amerikaner Alexander Graham Bell. Zusammen mit der bekannten Vorsilbe dezi- ergibt sich das Dezibel als ein Zehntel Bel.
Die Verdopplung des Pegels gegenüber dem Bezugspegel bedeutet so einen Anstieg von 6 dB. Ist der Pegel viermal so groß, sind es 12 dB Anstieg und ist er acht mal so groß, sind es 18 dB. Da die Vollaussteuerung die Obergrenze der möglichen Aussteuerung vorgibt, haben die Pegelangaben auf Aussteuerungsmessern negative Vorzeichen. Die Hälfte sind hier -6 dB, ein Viertel -12 dB usw.
In der Praxis wird er Umgang mit den Dezibel allerdings durch zwei Umstände erschwert:
-
Zum einen ist die Bezugsspannung für Dezibel leider regional verschieden:
In Europa sind es im Studiobereich 0,775 V, was der Spannung entspricht, die an 600 Ohm 1 mW Leistung umsetzt. Absolute Pegel, die sich auf diese Bezugsgröße beziehen, erkennt man an ihrem Zusatz: Sie heißen dBu oder (auf die Leistung bezogen) dBm. 0 dBu sind also 0,775 Volt, +6 dBu 1,55 Volt, +12 dBu 3,1 Volt usw.
Vor allem im angelsächsischen Raum wird jedoch 1 V als Bezugsgröße verwendet; absolute Pegel heißen hier dBV. 0 dbV sind 1 V, +6 dB sind 2 V etc. -
Zum anderen hängt die Bezugsgröße für Aussteuerungsanzeigen mit dB-Angaben von dem Umfeld ab, in dem sie sich befinden und für das sie eingemessen wurden: Die übliche Vollaussteuerung liegt
bei Consumer-Elektronik bei -10 dBV oder -7,78 dBu (~ 0,316 V),
in Tonstudios bei +1,78 dBV oder +4 dBu (~ 1,228 V), und
im Rundfunk (EBU und ARD) bei +3,78 dbV oder +6 dBu (~ 1,550 V);
d.h. die jeweiligen Aussteuerungsgeräte zeigen bei diesen Werten jeweils 0 dB an. Im Rundfunkbereich erfolgt die Skalierung der Aussteuerungsmesser zudem noch in dBFS (FS steht für full scale), wobei die +6 dBu Vollaussteuerung gleich -9 dBFS sind.3
Alles klar?
Bei Aussteuerung von für den Austausch produziertem Audiomaterial muss man sich also immer darüber im Klaren sein, in welchem Umfeld man produziert und für welches Umfeld produziert wird. Als Faustregel für den freien Rundfunk-Audio-Worker kann dabei gelten: Der Maximalpegel eines Produkts sollte -6 dB auf dem Aussteuerungsmesser der heimischen Software nicht übersteigen, um die 0 dB-Grenze im Radiostudio nicht zu verletzen.
Vom technischen Aufbau her kann die elektrische Schall-Übertragung auf zwei Arten realisiert werden, die unterschiedlich anfällig gegenüber Störungen, etwa durch Funkeinstrahlung, sind: Als einfache asymmetrische oder als kompliziertere symmetrische Verbindung.
-
Bei der asymetrischen Verbindung werden die elektrischen Signale in einem Leiter (Kabel) mit Bezug zu einem Potential (Masse) übertragen, wobei die Masse in der Regel auf der Abschirmungsummantelung (meist eine Metallfolie) liegt. Störungen, die diese Abschirmung durchdringen, wirken sich hier voll auf das Signal aus.
Eine solche Verbindung ist technisch allerdings einfach und kostengünstig zu realisieren, da man nur je ein einpoliges, abgeschirmtes Kabel und zweipolige Steckverbindungen pro Kanal braucht. Sie findet daher vor allem im Consumer-Bereich breite Verwendung. -
Bei der symetrischen Verbindung werden die elektrischen Signale bipolar, also mit Hilfe zweier Leiter unterschiedlicher Polarität übertragen. Zusätzlich schützt eine Abschirmungsummantelung (auch hier in der Regel die Masse) vor Störungseinstreuungen. Störungen, die diese Abschirmung durchdringen, wirken sich jetzt auf die beiden gegensätzlich gepolten Leiter hinsichtlich der Polarität in gleicher Richtung aus, können daher beim Empfänger, etwa einem Eingangsverstärker, der als Differenzverstärker arbeitet, wieder kompensiert werden.
Eine solche Verbindung ist technisch natürlich aufwendiger (und damit teurer), was man schon an den zweipoligen Verbindungskabeln und dreipoligen Steckern pro Kanal erkennt. Die verwendeten Ein- und Ausgangsgeräte müssen zudem entsprechende Ein- und Ausgänge für eine symetrische Verbindung bereitstellen (nicht nur zufällig passende Steckdosen!).
Ton in Materie - analoge Schall-Konservierung
Gäbe es nur die elektrische Tonübertragung, wäre der Rundfunk ein reines Live-Medium. Schon zu Beginn seiner Entwicklung in den 20iger Jahren des letzten Jahrhunderts sendete der Rundfunk jedoch ganz wesentlich auch aufgezeichnete Schallereignisse zunächst von Schall- oder Wachsplatte, später vom Tonband bzw Kassettenrekorder.

Die älteste Form der analogen Schallkonservierung ist wohl die Schallplattenaufzeichnung4, die im Prinzip sogar ohne elektrische Übertragung und Verstärkung durch unmittelbare Umwandlung der Schallwellen möglich ist (Gramophon).
Hier setzen entweder die Schallwellen selbst, gebündelt durch einen Trichter, oder die elektrischen Spannungsignale, in die das Mikrophon unsere Schallwellen verwandelt hat, die Nadel des Plattenschreibers in - den Schallwellen entsprechende - Schwingungen. Die Nadel ihrerseits überträgt diese Schwingungen auf das Material (Wachs) der Platte in eine spiralförmige Rille, die entsprechend der Amplitude des Schallsignals ausgelenkt wird. Wird die Platte abgespielt, setzt die so geschriebene Auslenkung der Plattenrille, die Abtastnadel wieder in dieselben Schwingungen, die dann entweder (beim alten Grammophon) direkt über einen Trichter verstärkt in Luftschwingungen verwandelt, oder (beim moderneren Plattenspieler) mittels eines Elekromagneten in elektrische Spannungssignale verwandelt werden, die - elektrisch verstärkt - die Membran eines Lautsprechers in Schwingung versetzen und dadurch wieder jene Luftschwingungen erzeugen, die unser Mikrophon anfangs aufgefangen hatte. Wir haben es hier also mit einer unmittelbaren oder mittelbaren Übertragung der Luftschwingung in das Material des Tonträgers, genauer: in seine äussere Form, zu tun.
Ähnlich bei Tondraht- und Tonbandaufzeichnung5: Hier wird jedoch nicht die Schwingung selbst in die äußere Form des Materials geschrieben, sondern die Spannungsschwankungen des elektrischen Signals, die die Pegelschwankungen dieser Schwingung repräsentieren, werden als Magnetisierungsschwankungen des Drahts oder von Metalloxid-Partikeln auf dem Tonband konserviert.
Wie schon bei der elektrischen Übertragung werden die Pegel auch bei der analogen Schallkonservierung kontinuierlich und lückenlos aufgezeichnet; genauer: Die Pegelschwankungen der akustischen Schwingung oder die ihr entsprechenden Spannungsschwankungen des elektrischen Übertragungsmediums werden in entsprechende Schwankungen von Materialeigenschaften des Aufzeichnungsmediums (äußere Form, Magnetisierung) übertragen. Auch hier findet keinerlei Sampling statt, allenfalls eine Diskontinuität der Pegelabfolge durch mangelnde Materialdichte des Aufzeichnungsmediums*.
Anders als bei der elektrischen Übertragung ist die Wiedergabe-Geschwindigkeit der Pegelfolge bei analogen Aufzeichnungen jedoch nicht auf die ursprüngliche Echtzeit beschränkt: Die Platte kann schneller oder langsamer als bei der Aufnahme abgespielt, das Band kann schneller oder langsamer als bei der Aufnahme am Tonkopf vorbeigeführt werden, was faktisch einer falsch deklarierten Abtastrate entspricht und das wiedergegebene Signal entsprechend verändert.
Beim Tonband kann zudem auch die Reihenfolge von aufgezeichneten Pegelfolgen und damit die Reihenfolge von Audiosignalen nach Aufzeichnung verändert werden, da das Band auseinander geschnitten und in veränderter Reihenfolge wieder zusammen geklebt oder ein Teil des Bandes und damit des aufgezeichneten Audiosignals entfernt werden kann. Gerade für den Rundfunk, der diese Technik seit 1939 einsetzte6, eröffnete das enorme Möglichkeiten: Versprecher konnten nachträglich entfernt und aufgezeichnetes Audio nach Bedarf angeordnet werden.
Im Laufe des letzten Jahrhunderts wurde die analoge Aufzeichnungstechnik zudem immer weiter perfektioniert, ermöglichte schließlich qualitativ hochwertige Schallaufzeichnung und - wiedergabe (High-Fidelity), seit Ende der 50iger Jahre auch mehrkanalig in Stereo oder gar Quadrophonie und war jahrzehntelang der Standard in Rundfunk und Unterhaltungsindustrie.
Trotz aller technischer Weiterentwicklung hatte die Steigerung der Qualität analoger Aufzeichnungen jedoch eine prinzipbedingte Beschränkung: das Materialrauschen des Aufzeichnungmediums. Da die akustische Schwingung als Folge ihrer Pegelschwankungen in Materialeigenschaften eines Tonträgers (Auslenkung der Rille, Magnetiserung einer Metallbeschichtung) übertragen wird, muss dieser Tonträger bei Aufnahme und Wiedergabe kontinuierlich an einem Tonabnehmer (Nadel, Tonkopf) vorbeigeführt werden. Schon das bloße Vorbeiführen eines unmodulierten Tonträgers am Tonabnehmer erzeugt jedoch selbst Signale: das sog. Grundrauschen des Tonträgers. Und die Höhe dieses Grundrauschens reduziert die Bandbreite der möglichen Lautstärke des aufzuzeichnenden Signals, seinen Dynamikumfang:
") Liegt das Grundrauschen etwa bei -37 dB, wie bei einem der ersten Tonbandgeräte von
1939, kann das leiseste Signal, das aufgezeichnet werden kann, nur noch bei ca. -31 dB
liegen, da das menschliche Ohr ein Signal-Rausch-Verhältnis von ca. 6 dB braucht, um das
Signal vom Rauschen unterscheiden zu können. Da das lauteste Signal nur bei der
Vollaussteuerung von 0 dB liegen kann, ergab dies einen Dynamikumfang von 31 dB.
Pech für die leisen Violinpassagen eines Klassikkonzerts, die so im Rauschen untergingen!
Liegt das Grundrauschen etwa bei -37 dB, wie bei einem der ersten Tonbandgeräte von
1939, kann das leiseste Signal, das aufgezeichnet werden kann, nur noch bei ca. -31 dB
liegen, da das menschliche Ohr ein Signal-Rausch-Verhältnis von ca. 6 dB braucht, um das
Signal vom Rauschen unterscheiden zu können. Da das lauteste Signal nur bei der
Vollaussteuerung von 0 dB liegen kann, ergab dies einen Dynamikumfang von 31 dB.
Pech für die leisen Violinpassagen eines Klassikkonzerts, die so im Rauschen untergingen!
Nun lag der Dynamikumfang späterer Geräte deutlich höher, schon bei der AEG K4 von 1941 waren es ca. 57 dB. Bei jeder analogen Kopie des aufgezeichneten Audiomaterials verdoppelt sich jedoch auch das Grundrauschen, sinkt also der Dynamikumfang.
Auch bei der Verkleinerung der Geräte und der dadurch notwendigen Verlangsamung der Bandgeschwindigkeiten stellte das Grundrauschen des Tonträgers trotz aller entwickelten Rauschunterdrückungssystem, wie Dolby™ oder Telcom™, immer wieder ein Problem dar, das sich letztlich erst durch die digitale Schallaufzeichnung umgehen ließ.
Ton in Zahl - aus analog wird digital
Was ändert sich nun mit der digitalen Schallaufzeichnung? Eigentlich nicht viel, aber Entscheidendes:
Statt die Pegelschwankungen, die die akustische Schwingungen repräsentieren, wie bei der analogen Aufzeichnung zunächst in Spannungsschwankungen (elektrische Übertragung) und dann in Schwankungen von physikalischen Eigenschaften des Tonträgers zu übertragen, wird jetzt der in regelmäßigen, definierten Zeitabständen abgetastete Wert des Pegels (bzw. der Wert der ihn repräsentierenden elektrischen Spannung) als Betrag, also als Zahl aufgezeichnet (digitalisiert). Es ensteht so eine Zahlenreihe von Pegelwerten (bzw. Spannungswerten) in definierten Abständen, die in der Regel binär codiert werden. Bei der Wiedergabe wird diese diskrete Folge von Pegelwerten wieder in eine Folge kontinuierlicher Spannungs- und damit Pegelschwankungen zurück verwandelt - und schließlich im Lautsprecher auch wieder in akustische Schwingungen.
Diese Digitalisierung des Audio-Signals, die in der Fachwelt auch gerne als lineare Puls-Code-Modulation [(L)PCM] bezeichnet wird, mag auf den ersten Blick vielleicht unnötig kompliziert erscheinen, bietet aber zwei wesentliche Vorteile:
-
Zum einen wird das Materialrauschen des Tonträgers, das bei analogen Aufzeichnungen so viel Ärger bereitet hat, jetzt nahezu vollständig bedeutungslos: Da das Signal durch Zahlen repräsentiert wird, wird seine Qualiät nicht davon beeinträchtigt, in welches Materialrauschen diese Zahlen eingebettet sind. Nur wenn die Zahlen vor lauter Materialrauschen (oder aus anderen Gründen) nicht mehr lesbar sind, geht das Signal oder Teile davon verloren; vorher verändert sich seine Qualität nicht. Anders als bei Analog-Aufnahmen verschlechtert sich die Qualität also auch nicht bei einer Kopie der Aufzeichnung.
-
Zum anderen bietet die Digitalisierung der Aufzeichnung auch die Voraussetzung dafür, dass das aufgenommene Audio von Computerprogrammen gelesen und mit Hilfe von Algorithmen weiterbearbeitet werden kann. Will man etwa eine bestimmten Zeitabschnitt der Aufnahme löschen oder kopieren, muss man nur die erste und letzte Zahl des entsprechenden Abschnitts in der Zahlenreihe identifizieren und diese zusammen mit allen dazwischen liegenden Zahlen löschen bzw. kopieren. Möchte man die Lautstärke eines bestimmten Abschnitts absenken, muss man nur die absoluten Beträge7 der zu diesem Abschnitt gehörenden Zahlen der Reihe um den jeweils gleichen Betrag reduzieren, usw.
Um ein digitalisiertes akustische Signal wieder in die korrekten akustischen Schwingungen zurückverwandeln zu können, müssen zusammen mit der Zahlenreihe von Pegelwerten natürlich auch die Definitionsdaten für diese Zahlenreihe entweder mit aufgezeichnet werden oder durch die Spezifikation eines verwendeten speziellen Aufzeichnungsmediums (wie z.B. durch das Red Book bei der Audio-CD) festgelegt sein. Ohne Kenntnis ihrer Definitionsdaten ist die Zahlenreihe wertlos.
Zu diesen Definitionsdaten gehört neben der Abtast- oder Samplingrate der Aufzeichnung, mit der wir uns im zweiten Abschnitt⇑ dieses Textes ja schon ausführlich beschäftigt haben, auch die Abtastgenauigkeit (auch: Auflösung, Sampling-Genauigkeit oder Samplingtiefe). Sie wird angegeben als Anzahl der Binärstellen der Zahl, mit denen der Pegelwert des Signals am gegebenen Zeitpunkt dargestellt (quantisiert) wurde. Bei einer Abtastgenauigkeit von z.B. 8 bit (wie bei Soundkarten vor 1995 üblich) kann der Wert des abgetasteten Pegels in 255 Quantisierungs-Stufen angegeben werden, bei einer Auflösung von 16 bit (CD-Standard) schon in 65.535, bei 24 Bit in 16.777.216 und bei 32 bit in 4.294.967.295 Stufen8.
Wichtig ist hier, sich klar zu machen, dass egal mit welcher Bittiefe die Pegel-Sample quantisiert werden, es immer einen maximalen (positiven bzw. negativen) Wert der digitalen Wortbreite gibt, der die Vollaussteuerung repräsentiert - eine letzte Quantisierungs-Stufe gewissermaßen, die zu einem Pegelwert nahe 0 dbFS führt. Wird dieser Pegelwert überschritten, gibt es keine Möglichkeit seiner digitalen Repräsentation mehr, da er jenseits des Definitionsrahmens der Quantisierung liegt. Übersteuerungen der Aufnahme, die schon analog zu unschönen Verzerrungen des Signals (Klirren) führen, haben bei Digitalaufnahmen eine völligen Zerstörung des Signals an der übersteuerten Stelle (Clipping) zur Folge und sind daher unbedingt zu vermeiden! Dem sog. Headroom (der Aussteuerungsreserve) kommt daher bei der digitalen Aufnahme und Mischung von Audiosignalen noch größere Bedeutung zu als analog und die durch diese Aussteuerungsreserve u.U. gegebene Übersteuerungsreserve fällt bei niedriger Samplingtiefe wegen der gröberen Skalierung geringer aus, als bei höherer Samplingtiefe.*
Zur Unterscheidung: Aussteuerungsreserve (Headroom) bezeichnet den Unterschied zwischen Nennpegel (0 dB am Aussteuerungsmesser) und technisch möglichem Maximalpegel (0 dBFS). Übersteuerungsreserve bezeichnet den möglichen Dynamikbereich des Signals, der in der Regel ungenutzt bleibt, aber für Signalspitzen evtl. zur Verfügung steht. Eigentlich sollte die Übersteuerungsreserve unterhalb des Headrooms enden, in der Praxis wird der Headroom jedoch oft auch als Übersteuerungsreserve genutzt.
Sowohl Samplingrate als auch Samplingtiefe bestimmen die Qualität der digitalen Aufzeichnung, entscheiden also darüber, wie genau die Aufzeichnung dem ursprünglichen akustischen Signal entsprechen kann. Für den europäischen Rundfunk hat die European Broadcast Union (EBU) hier eine Samplingrate von 48 KHz bei einer Samplingtiefe von 16 bit als Standard festgelegt - Werte, die auch der freie Audio-Homeworker nicht unterschreiten sollte.
Neben der Qualität bestimmen beide Größen natürlich auch die Datenmenge, die bei der digitalen Schallaufzeichnung anfällt, und damit wiederum die möglichen Speichermedien. Speichermedium kann jetzt zwar einerseits alles sein, was Zahlenreihen speichern kann, die Speicher- und Lesegeschwindigkeit des Speichermediums muss jedoch andererseits die Speicherung bzw. das Auslesen der pro Zeiteinheit anfallenden Datenmenge auch in eben dieser Zeit gewährleisten. Schon bei einer Aufzeichnung in 22,5 Khz und 8 bit sind dies etwa 1,3 MB pro Minute Monoaufzeichnung (ca. 2,6 MB Stereo), bei CD-Qualität (44,1 KHz und 16 bit) gut 5 MB pro Minute Mono (etwa 10 MB Stereo) und bei 48 kHz und 32 bit etwa 12 MB pro Minute Mono (ca. 24 MB Stereo).
Hollerith-Lochkarten, wie sie noch in den 60iger Jahren des letzten Jahrhunderts zur Datenspeicherung gebräuchlich waren, scheiden da als Aufnahme- und Abspieldatenträger sicherlich aus und dürften auch als Backup-Medium eher unhandlich sein (man bräuchte etwa 16250 dieser Lochkarten pro Minute Audio in 22,5 KHz/8 bit). Spezielle Daten-Bänder, wie die DAT (Digital-Audio-Tape) oder optische Speichermedien, wie die CD (Compact-Audio-Disk) erwiesen sich dagegen als durchaus geeignet.
Mit der zunehmenden Digitalisierung aller Bereiche der Gesellschaft dürfte sich allerdings die auf allgemein gebräuchlichen Datenträgern in Form einer Audio-Datei gespeicherte Schallaufzeichnung immer mehr durchsetzen. Hier haben sich zwei Dateiformate für LPCM-Audio-Daten etabliert, die sich sehr ähnlich sind:
-
AIFF, das vom Unternehmen Apple entwickelt wurde, auf dem von der Software- und Computerspiele-Firma Electronic Arts entwickelten Interchange File Formats (IFF) aufsetzt und als Standard-Audioformat auf Macintosh-Rechnern eingesetzt wird;
Dateiendung:.aiffoder.aif,sowie
-
RIFF-WAV, das auf dem von IBM und Microsoft für Windows 3.1 entwickelten Resource Interchange File Format (RIFF) für Multimediadaten aufsetzt, das selbst wiederum ebenfalls eine Modifikation von IFF ist, bei der hauptsächlich die Byte-Reihenfolge (Endianness) der Daten umgekehrt wurde (Big-Endian zu Little-Endian);
Dateiendung:.wav.
Beide Formate speichern neben den LPCM-Roh-Daten in einem Datei-Header auch deren Definitionsdaten. AIFF kann im Header darüber hinaus auch sog. ID3-Tags speichern, also zusätzliche Daten über Künstler, Titel, Komponist, Kommentare u.ä. Abgesehen von diesen ID3-Tags können beide Formate jedoch vollständig verlustfrei ineinander umgewandelt werden.
Erwähnenswert für den Rundfunkbereich ist darüber hinaus noch das Broadcast Wave Format (BWF), eine Weiterentwicklung des RIFF-WAV Formats, das erstmals 1997 von der European Broadcast Union (EBU) spezifiziert wurde und im Datei-Header die Speicherung zusätzlicher Daten, wie Qualität, Bearbeitungsdaten, Spitzenpegel, Möglichkeiten zur fortlaufenden Verlinkung meherer wav-Dateien u.ä. erlaubt9. Dateiendung ist zumeist ebenfalls .wav oder .bwf.
Dieses BWF-Format wurde seither von der EBU noch weiterentwickelt zum Multichannel Broadcast Wave Format (MBWF) oder RF64, das die ursprüngliche 32-bit-Beschränkung des RIFF-WAV Formats aufhebt und dadurch sowohl die Speicherung von LPCM-Rohdaten von mehr als 4 GigaByte pro Datei erlaubt, als auch die Aufzeichnung von mehr als 2 Kanälen pro Datei10, also auch lineare 5.1-Surround-Aufnahmen ermöglicht (wenn man will, sogar mit einer in der Datei enthaltenen seperaten Stereo-Abmischung). Dateiendung für das MBWF-Format ist ebenfalls .bwf, manchmal auch .rf64.
Ton gepresst - komprimiertes oder reduziertes digitales Audio
Wie bereits erläutert, fallen bei der linearen digitalen Schallaufzeichnung beachtliche Datenmengen an, die gerade zu Beginn des Internetzeitalters sowohl die Kapazitäten der üblicherweise in Homecomputern verbauten Datenträger als auch die Übertragungskapaziät privater Modem-Leitungen schnell an ihre Grenzen kommen ließ. Und auch heutzutage, so wohl die Erfahrung aller Computernutzer, ist die Größe vorhandener Datenträger im Zweifelsfall immer zu klein.
Nun kann man die anfallende Datenmenge natürlich auf Kosten der Qualität reduzieren, indem man Samplingrate und/oder Samplingtiefe reduziert - ein Verfahren was anfangs auch oft praktiziert wurde, auf Dauer vor allem bei Musikaufnahme aber eher unbefriedigend war.
Von verschiedenen Unternehmen, Forschungsinstituten und Gruppen von freien Programmierern wurden daher im Laufe der Zeit verschiedene Verfahren und Dateiformate entwickelt, um die Größe der Audiodateien und damit den anfallenden Datenstrom beim ihrem Einlesen, gemessen in (kilo)bits per second (kbps), zu minimieren. Prinzipiell kann dabei zwischen zwei Ansätzen bzw. Dateiformat-Klassen unterschieden werden: der verlustfreien (lossless) Datenkompression und der mit Datenverlust (lossy) verbundenen Datenreduktion.
Datenkomprimierte Audio-Formate
Bei Datenkompression wird die ursprüngliche LPCM-Audiodatei mit speziellen Algorithmen bearbeitet, die denen von Archiv-Programmen ähnelt. Die bekannten Archivprogramme (wie Zip, LZH, RAR o.ä.) haben zwar wenig bis keinen Effekt bei Audiodateien. Mit speziell für Audiodateien entwickelte Kompressionsalgorithmen lässt sich aber eine deutliche Datenkompression auf bis zu 30% der Usprungsgröße erzielen, wobei der Kompressionsgrad wesentlich vom Audiosignal selbst abhängt.
Vorteil dieses Verfahrens ist, dass keine Information des Ursprungssignals verloren geht: Die wieder dekodierte, also wieder entkomprimierte Audiodatei ist bitgleich zur ursprünglich komprimierten. Sofern ein Audio-Player die Dekodierung des genutzten Kompressionsverfahrens on the fly beherrscht, kann die komprimierte Datei auch ohne vorherige separate Dekodierung direkt abgespielt werden.
Datenkomprimierte Formate eignen sich daher sowohl zu Archivierung und Transport von digitalem Audiomaterial, als auch - wenn die verwendete Bearbeitungssoftware mit dem gewählten Format umgehen kann - als Standardformat. Allerdings sollte man als freier Digital-Heimwerker im Zweifelsfall immer davon ausgehen, dass der Auftraggeber mit dem verwendeten lossless Kompressions-Format nichts anzufangen weiss!
Die bekanntesten lossless Codecs sind11:
-
Free Lossless Audio Codec (FLAC):
ein seit 2000 von einer Gruppe freier Programmierer entwickelter freier quelloffener Lossless-Codec, der neben eigenen tags auch RIFF- und AIFF-Metadaten mit einbetten kann.
Dateiendung:.flac
Webseite: https://xiph.org/flac.
Kodierprogramm (gibt es für alle Betriebssysteme): flac, Bibliothek: libFlac,
Dateien können von zahlreiche Abspielprogramme, auch auf Android Smartphones direkt wiedergegeben und von vielen Bearbeitungsprogrammen direkt geladen werden. Mittlerweile beginnt sich FLAC auch als Format für Musikverkäufe im Internet zu etablieren und sollte, will man die gekaufte Musik in seinen Radio-Beiträgen verwenden, auch jedem mp3 vorgezogen werden. -
Apple-Lossless Audio Codec (ALAC):
ein von der Firma Apple entwickelter ursprünglich proprietärer Lossless Codec, der 2011, nachdem durch reverse engeniering auch freie Enkodier- und Dekodier-Programme entstanden waren, von Apple unter die open-source Apache-Lizenz gestellt wurde.
Dateiendung:.m4aoder.mp4(Achtung: Dateien mit diesen Endungen können auch datenreduziertes Audio enthalten!)
Kodierprogramme: iTunes, ffmpeg
Dateien können vor allem auf den Geräten und von Programmen der bunten Apple-Welt wiedergegeben werden, aber auch von manch anderen. -
WavPack:
Ein von David Bryant seit 1998 entwickelter quelloffener Codec, der sowohl lossless als auch verlustbehaftet kodieren kann und den auch das Archivierungsprogramm WinZip (seit Version 11) verwendet um WAV-Dateien zu archivieren.
Dateiendungen:.wvundwvc
Webseite: www.wavpack.com
Kodierprogramm (alle Betriebssysteme): wavpack
Auch mit wavpack erzeugte Dateien können von zahlreiche Abspielprogramme direkt wiedergegeben und von vielen Bearbeitungsprogrammen direkt geladen werden. -
Windows-Media-Audio-Lossless (WMA):
Auch Microsoft’s proprietärer Codec hat eine Möglichkeit der lossless Kodierung, wird in der Regel aber für verlusthafte Kodierung genutzt. Die Dateien können zudem DRM-kopiergeschützt sein.
Dateiendung:.wma(Auch hier ist die Dateiendung kein Indiz auf lossless Codierung, eher auf’s Gegenteil)
Datenreduzierte Audio-Formate
Beim datenreduzierenden Verfahren wird das Audiosignal der ursprüngliche LPCM-Audiodatei auf Grundlage psycho-akustischer Modelle, wie sie bereits in den 60iger Jahren vom Frauenhofer Institut entwickelt wurden, zunächst daraufhin untersucht, welche der darin enthaltenen Informationen vom normalen menschlichen Ohr u.U. gar nicht wahrgenommen werden können (etwa zu hohe, zu niedrige oder sich überlagernde Frequenzen u.ä.). Diese werden aus dem Signal entfernt, bevor dann ebenfalls eine Datenkompression erfolgt. Anders als beim nur datenkomprimierenden Verfahren kann hier auf die Parameter der Datenreduktion und der Anwendung bzw die Auswahl der psycho-akustischen Modelle beim Kodieren meist Einfluss genommen werden.
Vorteil dieses Verfahrens ist eine höhere Reduktion der Dateigröße auf bis zu 10% der Ursprungsgröße. Auch hier kann die reduzierte Datei ohne vorherige separate Dekodierung abgespielt werden, sofern der Player die Dekodierung on the fly beherrscht.
Nachteil ist jedoch, das die Audio-Daten des Ursprungssignals unwiederbringlich reduziert wurden. Zwar kann auch die datenreduzierte Datei wieder zu linearem PCM aufgeblasen werden, das aufgeblasene Signal entspricht jedoch nicht mehr dem linearen Ursprungssignal, da für die fehlenden Informationen nur Nullen gesetzt werden können. Ganz problematisch wird es, wenn das Signal mehrfach hintereinander kodiert, entkodiert und zwischendurch womöglich noch leicht bearbeitet wird. Da immer mehr Information aus dem Ursprungssignal durch Nullen ersetzt wird, können hörbare sog. Kaskadierungseffekte entstehen bis hin zur vollständigen Zerstörung des Signals.
Datenreduzierte Formate eignen sich daher bestenfalls für Endprodukte, die über langsame Internetverbindungen übertragen werden sollen, keinesfalls für Audiomaterial, das noch weiter bearbeitet werden soll!
Die bekanntesten verlustbehafteten lossy-Codecs sind wahrscheinlich die von der Moving Picture Experts Group (MPEG) bereits 1993 im MPEG I-Standard und später im MPEG IV-Standard definierten Formate:
-
MPEG I, layer 2 (
.mp2,.mus):
Dieses Format ist insofern interessant, als es im Wesentlichen dem Masking pattern adapted Universal Subband Integrated Coding And Multiplexing, kurz MUSICAM (Dateiendung:.mus) entspricht, das im Rahmen der Entwicklung von DAB von EUREKA entwickelt wurde und heute wohl in den meisten Rundfunkanstalten der Standard für datenreduziertes Audio ist, und zwar kodiert als 384 kbps Stereo, also 192 kbps pro Mono-Spur. Tatsächlich ist dieses Musicam-Format relativ wenig anfällig für Kaskadierungseffekte.
Erstellen kann man mp2-Dateien auch mit dem open-source-Programm TwoLAME.
Aber Achtung: mus-Dateien haben einen etwas anderen Header als im MPEG-Standard, u.a. ist in ihnen ein Abbild der Höhenkurve des Audios gespeichert, so dass Dateien nach reinem MPEG-Standard von Programmen in den Anstalten zwar eingelesen werden können, aber u.U. ohne Höhenkurve dargestellt werden. Diese erscheint erst nach Abspeichern und erneutem Laden. -
MPEG I, layer 3 (
.mp3):
Diese Format kennt wohl jeder, es wurde parallel zu MP2 entwickelt und verwendet ein ähnliches Verfahren12 wie MP2, wendet psycho-akustischen Reduktionen jedoch viel intensiver an und ist daher anfälliger für Kaskadierungseffekte, vor allem bei kleinen Bitraten.
Die qualitativ besten Ergebisse erhält man bei Kodierungen mit 320 kbps joint-stereo - und darunter sollte man heutzutage auch nicht bleiben, wenn man hörbare Artefakte des Urspungssignals vermeiden will. Allerdings bietet das Format die Möglichkeit variabler Bitraten bei der Kodierung, so dass man selbst bei best möglicher Qualität Dateien erhalten kann, die nur etwa 20% der Größe der linearen Ausgangsdatei haben.
Erstellt werden können mp3-Dateien u.a. mit dem Open-Source-Programm Lame oder mit Programmen die die Bibliothek liblame verwenden. Alle Patente bezüglich der MP3-Kodierung, die eine legale Nutzung des Formats anfänglich erschwerten, sind übrigens spätestens seit 2017 weltweit erloschen. -
MPEG IV, Advanced Audio Coding (AAC) und High Efficiency Advanced Audio Coding (HE-AAC oder AAC+ und AAC+ v2)
erlauben höhere Daten-Reduktionsraten bei ähnlicher Qualität, sind aber sehr anfällig für Kaskadierungseffekte
mögliche Dateiendungen:.aac, .3gp, .mp4, .m4a, .m4b, .mpg, .mpeg
Daneben gibt es noch diverse andere verlustbehaftete Formate wie Microsofts WMA oder das aus der Open-Source Gemeinde stammende Ogg-Vorbis (.ogg).
|
⇐ zurück zu AudioWorker's Place |
weiter ⇒ zu Aufnahme-Wissen I: Mikrofon |
Anmerkungen
-
Diese Abbildung stammt aus einer Lehrveranstaltung von Berthold Cogel am Zentrum für Angew. Informatik der Universität Köln (Dez. 2000), wurde hier nur etwas aufgehübscht:
www-f.rrz.uni-koeln.de/RRZK/kurse/unterlagen/audio/akustik.html.
Das Zentrum wurde mittlerweile allerdings aufgelöst. ↩ -
Wer Spaß an Mathematik hat, mag sich dies auch gerne genauer anschauen. Als Einstieg empfehle ich den entsprechenden Wikipedia-Artikel. Uns soll hier die einfache Fassung reichen! ↩
-
Wer es genauer wissen will: de.wikipedia.org/wiki/Schallplatte. ↩
-
Die technischen Details der Tonbandaufzeichnung sind recht komplex. Wer’s genauer wisssen will, hier ist ein Einstieg: de.wikipedia.org/wiki/Tonbandgerät. Einen Überblick über die Geschichte der Technik findet man auf den Webseiten des virtuellen Tonband-Museums Wiesbaden von Dipl. Ing. Gert Redlich.
Uns geht es im Folgenden nur um die Abgrenzung zur Digitaltechnik. ↩ -
Das erste funktionierende Tonbandgerät, die AEG K1, wurde bereits auf der Berliner Funkausstellung 1935 vorgestellt, arbeitete allerdings noch mit beschichteten Papierbändern. 1939 wurde die Technik bei der Reichs-Rundunk-Gesellschaft eingeführt, jetzt mit Eisenoxid beschichteten Acetyl-Cellulose-Bändern (AEG K3) und ab 1941 auch mit hochfrequenter Vormagnetisierung (AEG K4), die erstmals einen Rauschabstand von 55-60 dB (gegenüber bisher 37 dB) und die Darstellung höherer Frequenzen ermöglichte. Ab 1943 wurde dann auch das später übliche beschichtete PVC-Band benutzt. ↩
-
es gibt u.U. auch negative Zahlen! ↩
-
8 bit: 128+64+32+16+8+4+2+1, also: 0 … 28 = 0 … 255;
oder signed, hier wird ein Bit gebraucht, um das Vorzeichen zu speichern:
-24/2 … 24/2-1 = -128 … 127
16 bit: 0 … 216 = 0 … 65535; oder signed: -32.768 … 32.767
32 bit: 0..232 = 0 … 4.294.967.295;
oder signed: -9.223.372.036.854.775.808 … 9.223.372.036.854.775.807
Bei der Bewertung dieser Größen ist allerdings noch zu bedenken, das eine Quantisierung im Pulsmodulationverfahren (PCM) auch nicht-linear erfolgen kann. Dies soll in diesem Text, um Irritationen zu vermeiden, jedoch unerwähnt bleiben. ↩ -
ITU-R BS.1352-3, Annex 1, s.a.: Broadcast Wave Format (BWF) user guide ↩
-
zur Multichannel-Nutzung des BWF-Formats siehe: EBU Recommendation R111-2007 - Multichannel use of the BWF audio file format (MBWF) ↩
-
Wer mehr lossless Formate haben möchte, schaue bei Wikipedia ↩
-
wer mehr wissen will: http://www.solarnavigator.net/sponsorship/mp3.htm ↩
site info
© 2007-2022 Klaus-M. Klingsporn | Erstellt mit webgen | Seite zuletzt geändert: 10.1.2022 | Impressum